OpenAIが音声AIを3つに分解。新しいリアルタイム音声モデルがAPIで使えるようになりました

OpenAIが2026年5月7日、3つの新しいリアルタイム音声モデルをAPIで提供開始しました!
リアルタイムAPIの中で、会話・翻訳・文字起こしという用途別の専門モデルラインナップが拡充された形ですね。
128Kトークンのコンテキストウィンドウにも対応していて、長時間の音声会話もカバーできるようになっています。
3行で押さえる
- OpenAIが音声AIを「1つのモデル」から「3つの専門モデル」に分解し、APIで提供開始
- 会話・翻訳・文字起こしがそれぞれ独立した形で使えるようになった
- 128Kトークン対応で長時間の音声セッションもサポート
音声AIって、今どうなってるの?
まず少し背景の話をしますね。
これまでの音声AIって、会話も翻訳も文字起こしも全部ひとつのモデルが一手に引き受ける設計だったんですよね。
いわば「なんでもこなすオールラウンダー」です。一見便利そうに聞こえるんですが、実はここに問題があって。
オールラウンダーってどのタスクに対しても「そこそこ」の精度しか出せないことが多いんですよ。
翻訳に特化したモデル、文字起こしに特化したモデルに比べると、どうしても見劣りしてしまう場面が出てきます。
それに、「会話の精度を上げたい」と思ってモデルを改善しようとしても、翻訳や文字起こし性能に影響が出てしまうリスクもある。
全部つながってるから、一か所いじると別の場所が揺れる、という感じです。
「全部入り」の音声AIには、こういうトレードオフがずっとついて回っていたんです。
今回OpenAIが発表したのは、そこへの答えのひとつです。
会話・翻訳・文字起こし、それぞれのタスクに専門モデルを用意して、それを組み合わせて使う設計に切り替えた。
ざっくりいうと、「ひとりの万能選手」から「3人の専門家チーム」にシフトしたイメージですね。
3つのモデル、何が違うの?
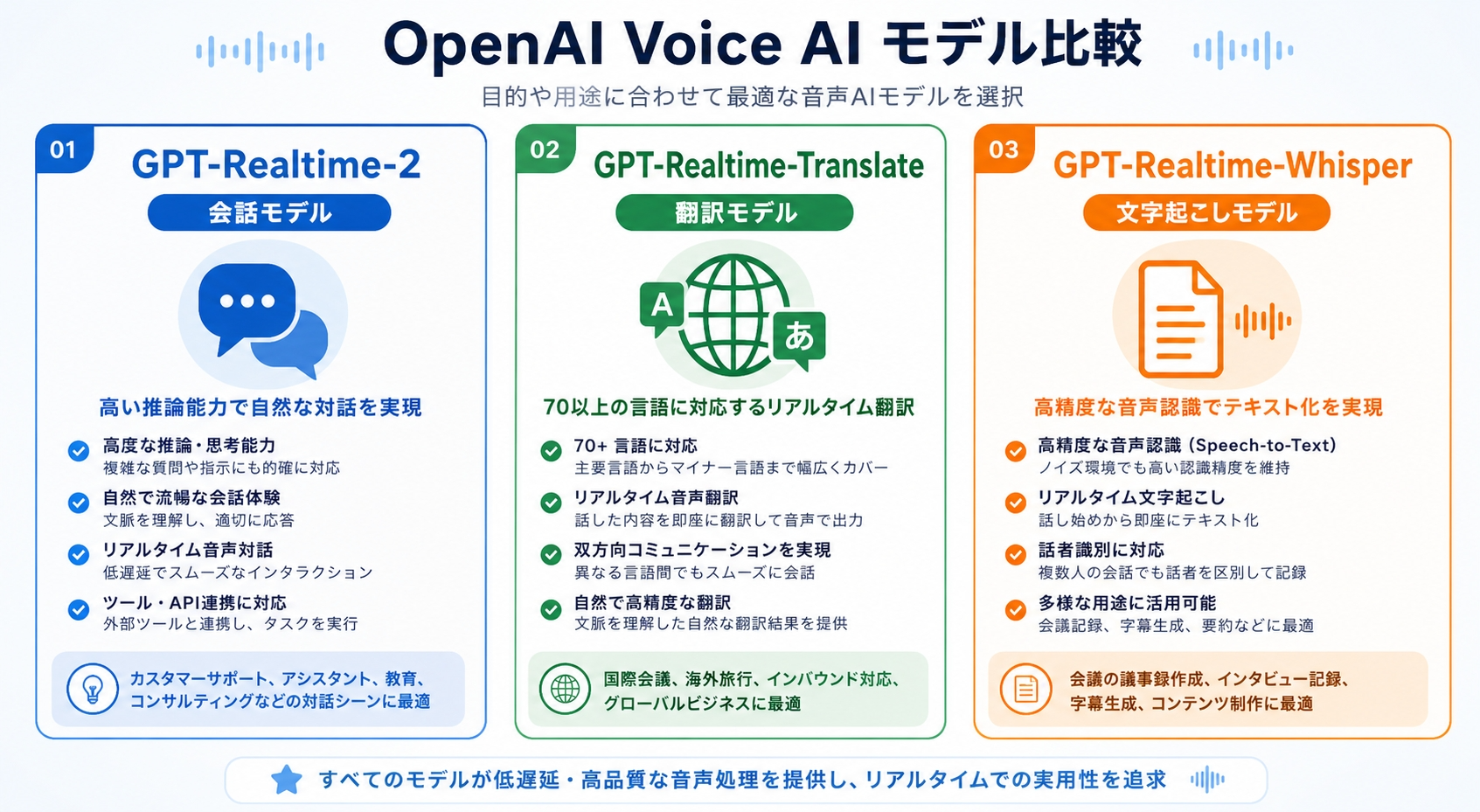
今回APIで提供されたのは以下の3モデルです。
GPT-Realtime-2(会話モデル)
高い推論能力を持つ、リアルタイム音声会話向けのモデル。複雑なリクエストを処理しながら、自然な会話の流れをキープできる設計になっています。
「高い推論能力」って具体的にどういうことかというと、たとえば「先週の打ち合わせの内容をふまえて、今日の議題への対応方針を考えて」みたいな、文脈を丸ごと把握したうえで答えてくれる感じ。
音声で話しながら複雑な依頼をしても会話が途切れずに続くイメージですね。
GPT-Realtime-Translate(翻訳モデル)
70以上の入力言語から13の出力言語へのリアルタイム翻訳ができるモデルですね。
「話者のペースで翻訳する」という設計が特徴で、相手が話しているスピードに合わせて訳出していく動きが想定されています!
会議やプレゼンで「話している内容をその場で別の言語に変換したい」という場面にフィットしそうですよね。
GPT-Realtime-Whisper(文字起こしモデル)
音声をテキストに変換することに特化した新モデルです。
Realtime API向けに新たに提供される文字起こしモデルとして位置づけられています。
文字起こし単体に集中できるので、たとえば会議録音から議事録を自動生成するような用途では、会話モデルより精度面で使いやすくなると見られています。
何ができるようになるの? ― 活用イメージ
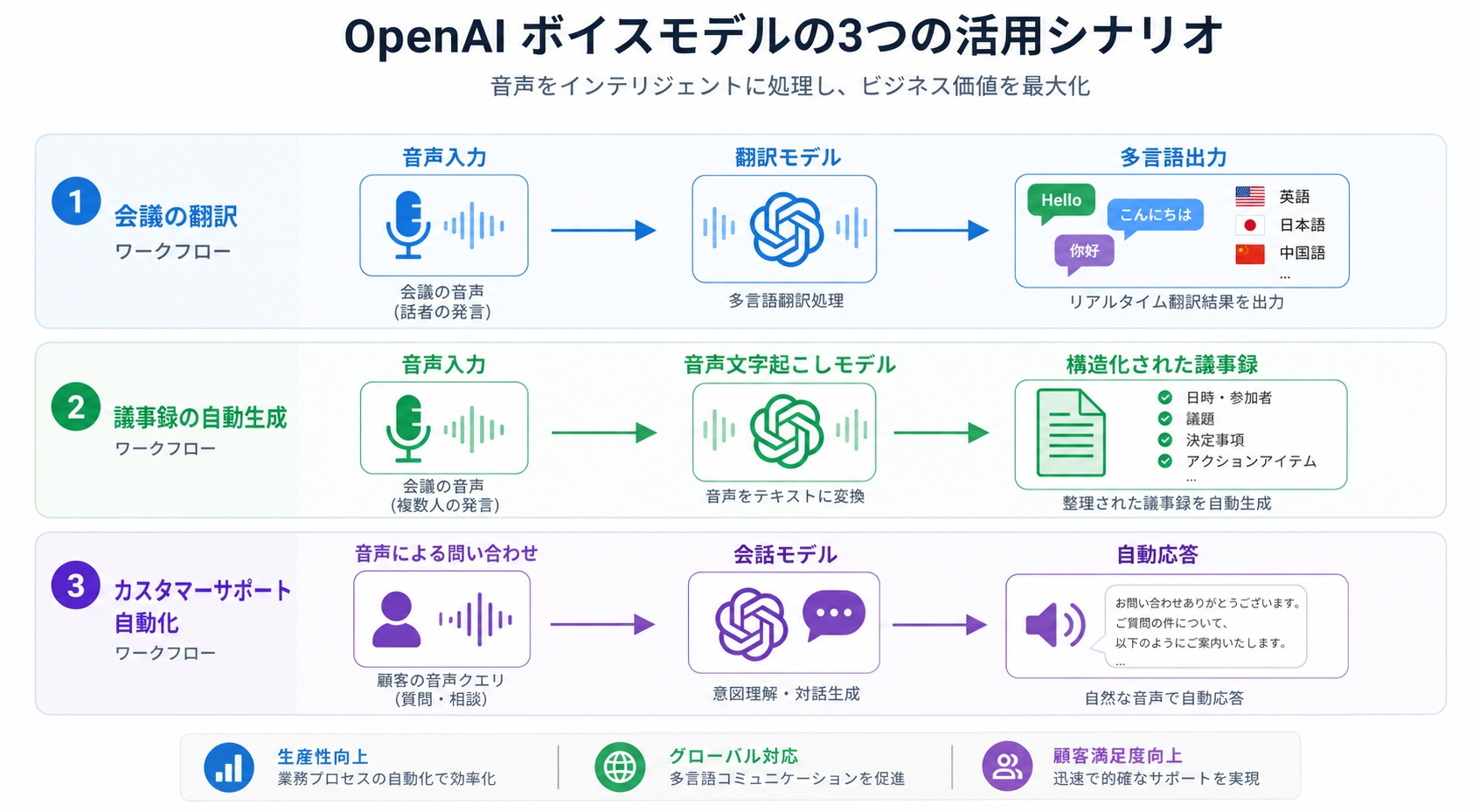
これらのモデルを組み合わせることでどんなことができそうでしょうか?
公式からの発表をもとに整理しつつ活用アイデアもあわせて紹介しますね。
公式が想定しているユースケース
エンタープライズ向けの音声エージェントが主なユースケースとして挙げられていますね。
たとえば、ユーザーが音声で操作・質問できるカスタマーサービスエージェントや、コールセンター業務の一部を担うエージェントの構築などが想定されています。
また、教育プラットフォームでの音声対話学習、メディア・放送分野でのリアルタイム翻訳、クリエイタープラットフォームでの多言語コンテンツ配信といった用途も視野に入ってくると考えられています!
活用アイデア(参考)
以下は一般的な用途として考えられる活用例です。
まだ確定した事例ではなくモデルの仕様から想定できるアイデアとして参考にしてください。
多言語対応カスタマーサポートの自動化
GPT-Realtime-Translateを軸にすることで、多言語対応のサポートエージェントが構築できそうなきがします!
問い合わせ対応の言語切り替えを人手でまかなっていた部分をモデルに委ねるという活用が考えられますよね。
会議のリアルタイム翻訳+議事録生成の組み合わせ
翻訳モデルで会議の内容をリアルタイムに別言語へ変換しながら文字起こしモデルで音声テキスト化を並走させることで、「翻訳済みの議事録」を自動生成するという組み合わせもあり。
音声UIを持つアプリへの組み込み
GPT-Realtime-2の会話能力と、Whisperモデルの高精度な文字起こしを組み合わせることで、音声操作ができるアプリのバックエンドとして活用できそうです。
開発者目線で気になるポイント
WebRTCによる低遅延への取り組み
今回の接続にはWebRTCを活用していて、低遅延とグローバルスケールを実現しています(openai.com/api/docs/guides/realtime-webrtc)。WebRTCというのはブラウザやアプリでリアルタイム通信を行うための技術基盤で音声や映像をほぼ遅延なく届けるためのプロトコルですね。
WebRTCの活用によりグローバルスケールでの低遅延とシームレスな会話のターンテイキング(話者交代)を実現することをOpenAIは目指しているとされています。
ターンテイキングというのは「相手が話し終わったタイミングで自分が話し始める」という、会話の自然な切り替わりのこと。
これがうまく機能しないとAIが「話しかけたのに少し待たされる」「相手の発話が終わる前に返事が来る」という体験になってしまいますよね。
そこを改善するのが今回の設計の目的のひとつです。
128Kトークンで、どのくらいの会話に対応できるの?
128Kトークンという数字が出てくると、「それって何分くらいの会話なの?」と思いますよね。
あくまで目安として考えてほしいんですが、一般的にテキストで1トークン≒日本語0.5〜1文字程度、英語では0.75単語程度の対応関係といわれています。
音声の場合は変換後のテキスト量で計算されるため一概には言えませんが、かなり長い会話セッションを1つのコンテキストの中で扱えるスペックが確保されたと見ていいかなと思います。数十分規模の音声セッションをそのまま保持しながら対話を継続できる設計、という理解で問題ないかと!
これは特に長時間にわたるサポート対応や、複数ターンの議論を前提とするエージェント設計において意味を持ってきそうですね。
エコシステムへの統合とオーケストレーション設計
Realtime APIを通じてOpenAIの既存APIエコシステムに統合されていて、Agents SDKとの連携にも対応しています。
個別タスクを専門モデルへ割り当てられるので、「翻訳が必要な場面ではGPT-Realtime-Translateを呼び出し、文字起こしが必要な場面ではGPT-Realtime-Whisperを使う」というようなオーケストレーション設計が組みやすくなりました。
既存のOpenAI APIエコシステムと組み合わせながら構築できるのは、開発者にとって地味にうれしい変化ですよね。
価格体系
各モデルの料金(公式ページより)はこんな感じです。
- GPT-Realtime-2:入力 $32 / 100万トークン(キャッシュ済み入力 $0.40)、出力 $64 / 100万トークン
- GPT-Realtime-Translate:$0.034 / 分
- GPT-Realtime-Whisper:$0.017 / 分
翻訳・文字起こしモデルは「分単位課金」、会話モデルは「トークン単位課金」という違いも押さえておくといいですよ。どちらをメインに使うかでコスト試算のしかたが変わってくるので。最新の料金は公式料金ページ(https://openai.com/api/pricing/)でご確認ください。
まとめ
OpenAIの今回の発表は、リアルタイムAPIの中で用途別の専門モデルラインナップが拡充されたことを示すものですね。
- GPT-Realtime-2:複雑な会話・推論が必要な場面向け
- GPT-Realtime-Translate:70以上の入力言語から13の出力言語へのリアルタイム翻訳向け
- GPT-Realtime-Whisper:精度重視の音声文字起こし向け
それぞれを必要な場面で組み合わせる設計に変わったことで、開発者がより意図を持ってシステムを組み立てられる土台が整いましたね。
音声UIの実装や多言語サポートを検討しているプロダクトにとっては、選択肢の幅が広がったタイミングですよね。APIドキュメントを確認しながら自分のユースケースにどのモデルが合うかをまず試してみてください。
よくある質問
3つの音声モデルの違いは何ですか?
GPT-Realtime-2は高い推論能力を持つ会話モデル、GPT-Realtime-Translateは70以上の入力言語から13の出力言語へのリアルタイム翻訳モデル、GPT-Realtime-Whisperは音声テキスト変換に特化したモデルです。それぞれが独立したAPIとして提供されていて用途に応じて使い分けたり組み合わせたりできます。
日本語には対応していますか?
入力言語(70以上)には日本語が含まれているとされていて公式デモでも日本語の例が使用されています。翻訳先(出力)の13言語に日本語が含まれるかはAPIドキュメント(developers.openai.com)でご確認ください。
既存のOpenAI APIから使えますか?
はい、使えます。今回の音声モデルはRealtime APIを通じてOpenAIの既存APIエコシステムに統合されており、Agents SDKとの連携にも対応しています。既存のAPIアカウントや認証情報をそのまま使いながら新しいモデルにアクセスできるので、改めてセットアップし直す必要はないです。詳細はOpenAIの公式ドキュメントをご確認ください。
お気軽にご相談ください
AIを使った業務効率化、社内ツール開発、既存プロダクトへのAI機能追加、受託開発全般——上流の企画段階から実装・運用まで、まとめてご相談いただけます。
「これってAIで解決できるの?」「どこから手をつければいい?」という入口のご相談大歓迎です。
具体的な仕様が固まる前の壁打ちフェーズからぜひお気軽にご相談ください。
参考情報
- 公式発表ページ:https://openai.com/index/advancing-voice-intelligence-with-new-models-in-the-api/
- Realtime APIドキュメント:https://developers.openai.com/api/docs/guides/realtime
- 料金ページ:https://openai.com/api/pricing/



