デジタル庁「源内(GENAI)」全省庁18万人に展開するガバメントAIの全貌

「役所の仕事にAIは使えない」という認識、もう通用しないんですよね。
2026年5月現在、デジタル庁が開発したガバメントAI「源内(げんない)」が全省庁の約18万人を対象とした大規模パイロット(Release 2.0)の稼働段階に入っています。国会答弁の作成支援から法務調査、パブリックコメントの自動分類まで、行政業務の核心に踏み込んだAI活用が現実になりました。
本記事では、技術者・IT担当者向けに源内の仕様・機能・OSS構成・国産LLM選定基準を体系的に整理します。
源内(GENAI)とは何か
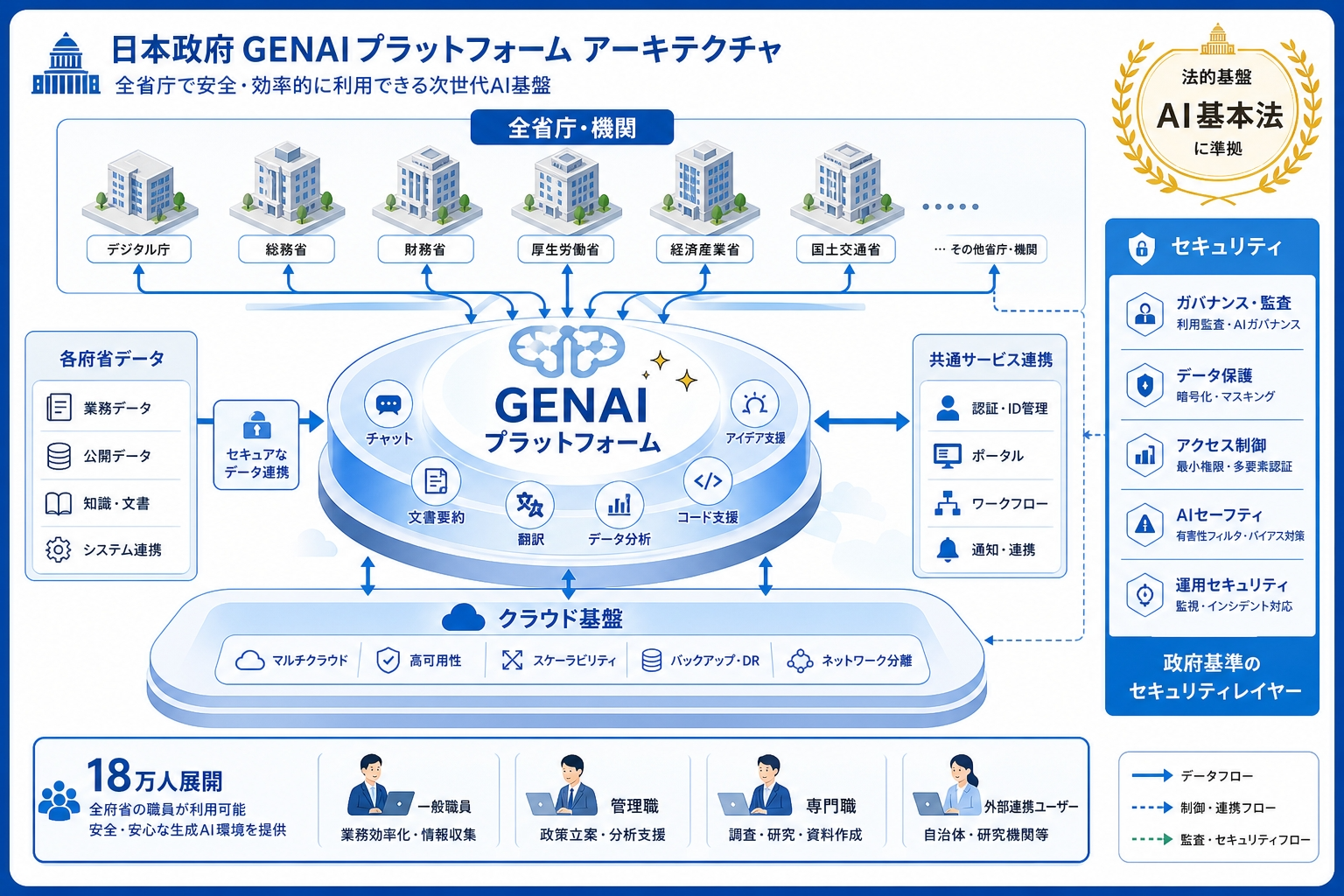
結論から言うと、ガバメントAI「源内」(英語名:Government AI “GENAI”) はデジタル庁が開発・運用する政府向け生成AIプラットフォームなんです。
全省庁の職員を対象として汎用的なチャット・文書作成機能から行政業務に特化したAIアプリケーションまでを一元的に提供します。
開発の法的根拠はAI基本法(2025年5月施行)およびAI基本計画(2025年12月策定)にあります。政府はAI基本計画の中で「公共サービスへの生成AI活用」を重点施策として位置づけており、源内はその中核インフラという立ち位置ですね。
公式情報は以下で参照できます。
出典:https://www.digital.go.jp/en/policies/genai
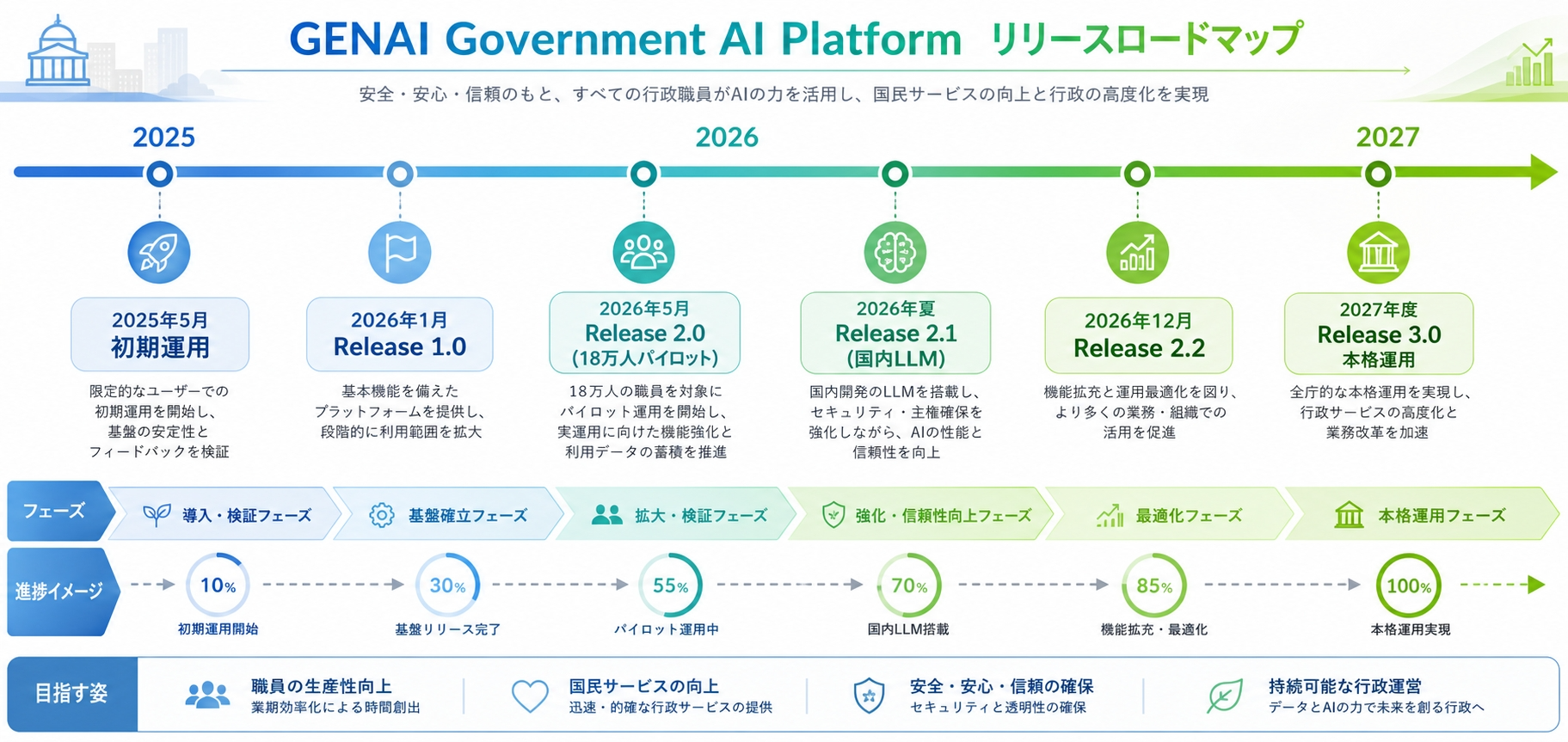
開発ロードマップ
源内の展開は段階的なリリース計画に沿って進んでいます。
| 時期 | フェーズ | 内容 |
|---|---|---|
| 2025年5月 | 初期運用 | デジタル庁内での運用開始 |
| 2026年1月 | Release 1.0 | 選定省庁での試用開始 |
| 2026年5月〜 | Release 2.0 | 全省庁約18万人への大規模パイロット |
| 2026年夏 | Release 2.1 | 国内LLM試験導入 |
| 2026年12月 | Release 2.2 | 高度なAIアプリ提供開始 |
| 2027年度〜 | Release 3.0 | 本格運用開始 |
現時点(2026年5月)は大規模パイロット(Release 2.0)の段階です。国内LLM試験導入(Release 2.1)は2026年夏に予定されていますが、詳細な選定プロセスは「将来予定」として公式に位置づけられています。
機能構成:汎用型と行政特化型の2層構造
源内の機能は大きく2種類に分かれます。まず1つ目が汎用型、2つ目が行政特化型です。
汎用型AI機能
| 機能 | 概要 |
|---|---|
| チャット | 業務上の質問・情報検索・ブレインストーミング支援 |
| 文書作成 | 草稿生成・構成提案 |
| 要約 | 長文書類の要点抽出 |
| 校正 | 文書の誤字脱字・表現の整合確認 |
| 翻訳 | 多言語間の文書翻訳 |
行政特化型AIアプリ
| アプリ名 | 英語名 | 対象業務 |
|---|---|---|
| 国会答弁作成支援AI | Diet Response Support AI | 質問主意書への答弁案作成支援 |
| 法務調査支援AI | Legal Research Support AI | 法令・判例調査の補助 |
| 行政文書分析 | — | 大量の行政文書の分類・抽出 |
| パブリックコメント分類 | — | パブコメ意見の自動分類・集計 |
| 委員会管理支援 | — | 会議体の議事・管理業務の支援 |
| 出張調整支援 | — | 出張手続きの効率化 |
ここがポイントで、国会答弁支援AIと法務調査支援AIは行政業務の中でも特に専門性が高い領域に踏み込んでいます。
「汎用LLMに業務データを組み合わせるRAG構成」をとっていると考えられますが、内部アーキテクチャの詳細は公式資料に明示されていません。
具体的な使用イメージ(活用アイデア(参考))
以下の3シナリオは、源内の機能仕様をもとに想定される活用例です。公式事例ではなく「活用アイデア(参考)」として示します。
シナリオ1:法令調査の時間を大幅に短縮する(行政担当者)
法改正対応の検討では、担当者が関連法令・過去の省令・通達を一から調べると数時間〜数日を要することがあります。法務調査支援AIに「〇〇法第△条の適用範囲と関連通達の一覧を整理してほしい」と入力することで、関連条文の一覧と要約を数分で出力できます。その後、担当者が内容を精査して最終的な判断を行う流れが想定されますね。
シナリオ2:住民向け文書のやさしい日本語変換(広報担当者)
行政文書は専門用語や長い文章構造が多く、住民に伝わりにくい表現になりがちです。汎用チャット機能または文書作成機能に原文を入力し「小学5年生にわかるやさしい日本語に書き直してほしい」と指示することで、わかりやすい文章の草稿を得られます。担当者はその草稿を確認・修正して最終化する形ですね。
シナリオ3:1000件のパブコメを分類・集計する(政策立案担当者・管理職)
パブリックコメントが大量に寄せられた場合、従来は担当者が一件ずつ確認・分類する作業に多くの工数がかかっていました。農林水産省の事例では、約8,000件のアンケート回答を複数のシナリオで仮説検定した結果、通常1名・2ヶ月かかる分析が約3日で完了したと公式に報告されています(2025年6〜8月実施)。パブリックコメント分類機能を活用することで、同様の大量分類・集計業務に応用できる可能性があります。
ただ、1点だけ注意があって、この農水省の事例は公式確認済みの単一事例であり、他省庁・他業務での一般的な処理時間を示すものではありません。
出典:https://www.digital.go.jp/en/policies/genai
国産LLM7選:なぜ国産か、どう選ばれたか
国産LLMを採用する3つの理由
- セキュリティ: 機密性2相当の行政情報を国内インフラで処理できる
- コスト: 海外クラウドAPIへの依存を減らし、長期的な運用コストを抑制できる
- 日本語精度: 行政用語・法令文体に特化した学習データの活用が可能
選定基準
デジタル庁が設定した選定基準は5点です。
- 国内開発のLLMであること
- 行政業務で実用可能な性能を持つこと
- デジタル庁ベンチマーク(50問)で優秀な結果を示すこと
- ハルシネーション対策・差別的表現への対応が確認されていること
- 機密性2情報を扱えるセキュリティ対策を備えていること
選定された7モデル
| モデル名 | 開発元 | 特徴 |
|---|---|---|
| tsuzumi 2 | NTTデータ | 30Bで1GPU動作・推論コストを大幅に削減できるとされている |
| cotomi v3 | NEC | 日本語特化・エージェント推論性能 |
| PLaMo 2.0 Prime | Preferred Networks | 独自開発による純国産モデル |
| Takane 32B | 富士通 | 量子化・特化型蒸留によるエッジ対応 |
| Sarashina2 mini | SoftBank | コンパクトサイズ・日本語ベンチマークで高いスコアを記録しているとされている |
| Llama-3.1-ELYZA-JP-70B | KDDI・ELYZA(共同応募体) | Llama 3.1ベースの日本語適応モデル |
| CC Gov-LLM | カスタマークラウド | 組織固有データへのカスタマイズ対応 |
NTTデータのtsuzumi 2は1GPU動作という特徴を持ち、クラウドへのフルアクセスが制限される環境での導入ハードルを下げます。KDDI・ELYZA(共同応募体)のLlama-3.1-ELYZA-JP-70BはMeta社のLlama 3.1をベースにした日本語適応モデルで、オープンウェイトモデルの活用という観点でも注目される構成です。
2026年夏のRelease 2.1での国内LLM試験導入に向けて、これらのモデルがどう組み込まれるかが今後の注目点ですね。
OSS化で何が変わるか
2026年4月24日、デジタル庁は源内のソースコードをGitHubで公開しました。
公開リポジトリ
| リポジトリ | URL | ライセンス |
|---|---|---|
| フロントエンド(genai-web) | https://github.com/digital-go-jp/genai-web | MIT主体・一部AWS ASL |
| バックエンド(genai-ai-api) | https://github.com/digital-go-jp/genai-ai-api | MIT + CC BY 4.0 |
ちなみに、フロントエンドのgenai-webはAWSが公開している「GenAI Use Cases(GenU)」を改修して開発されました。現在はGenUとは独立した構成となっています。
ライセンスはMIT主体ながら一部にAWSの Amazon Software License(ASL)が含まれる二層構造になっている点は押さえておいてください。
3クラウド対応テンプレート
OSS公開に合わせて、3つのクラウド環境向けデプロイメントテンプレートが提供されています。
- AWS向け:RAG(検索拡張生成)構成テンプレート
- Azure向け:LLMセルフデプロイテンプレート
- GCP向け:法令参照AI向け構成テンプレート
民間・自治体への波及
デジタル庁は公式に「地方自治体のAIサービス市場を刺激する」方針を示し、民間参入の促進を明記しています。OSS化により、自治体や民間企業が源内のコードベースを参照・改修して独自の行政AIを構築することが技術的に可能になりました。
ただ、1点だけ注意があって、全国自治体への具体的な展開ロードマップは2026年5月時点で公式発表がありません。「地方自治体向けの展開」と「全省庁約18万人のパイロット」は別スコープですので、混同しないようにしてください。
禁止事項は「政治的・差別的利用」「他システムへの攻撃」のみで、商用・非商用を問わず幅広い活用が可能な設計になっています。
出典:https://www.digital.go.jp/en/news/907c8e5d-2f4f-4bd7-9400-37c9f4221d7d
導入検討のためのチェックリスト
源内の設計思想から、組織がAIを業務導入する際に参考になる3つの設計軸を整理します。
軸1:セキュリティ要件の明確化
- 扱うデータの機密レベルを事前に定義する(公開情報・機密性1・機密性2など)
- 機密性の高いデータを処理する場合、クラウド外に出ないオンプレミス・プライベートクラウド構成を検討する
- LLMプロバイダーとのデータ取り扱い条項を確認する
軸2:LLM選択の基準設定
- 業務要件(日本語精度・推論コスト・レスポンス速度)を定量的に評価する
- 独自ベンチマーク(源内では50問)を設計し、汎用スコアだけで選定しない
- ハルシネーション発生率と差別的出力へのガードレールを評価項目に含める
軸3:段階的ロールアウトの設計
- 小規模パイロット(源内ではデジタル庁内)から始め、問題を把握してから拡大する
- 利用ログ・フィードバック収集の仕組みを本番前に整備する
- 「AIが出力した内容の最終確認は人間が行う」という運用ルールを先に策定する
よくある質問(FAQ)
Q1. 源内は民間企業や地方自治体も利用できますか?
現状(2026年5月)の源内プラットフォーム自体は中央省庁の職員向けなんです。ただしOSS化によりソースコードが公開されており、民間・自治体が独自にデプロイして活用することは技術的に可能です。デジタル庁は地方自治体のAIサービス市場を刺激する方針を公式に示していますが、具体的な全国展開ロードマップは未発表ですね。
Q2. ライセンスはどうなっていますか?商用利用できますか?
フロントエンド(genai-web)はMITライセンス主体ですが、AWSの Amazon Software License(ASL)が一部に含まれる二層構造なんです。バックエンド(genai-ai-api)はMITとCC BY 4.0の組み合わせ。禁止事項は「政治的・差別的利用」「他システムへの攻撃」のみで、商用利用は禁止されていません。利用前にライセンス条文の詳細を確認してください。
Q3. セキュリティ面で行政の機密情報を扱えますか?
国産LLM7モデルの選定基準の一つとして「機密性2情報を扱えるセキュリティ対策」が明示されています。ただ、機密情報の取り扱いはデプロイ環境・運用ポリシーによって大きく左右されます。自組織で導入する場合は、インフラ構成・アクセス制御・ログ管理の要件をセキュリティチームと別途設計する必要があります。
Q4. 国産LLM7モデルと海外モデル(GPT-4oなど)の違いは何ですか?
主な差異は「データ所在地のコントロール」「日本語に特化した学習」「行政用語への対応度」の3点です。tsuzumi 2はオンプレミスを含む国内環境で動作できる点が特徴の一つとされていますね。海外モデルとの性能差は業務内容によって異なるため、選定基準に沿ったベンチマーク評価を行うことが求められます。
Q5. 源内の本格運用はいつ始まりますか?
公式ロードマップによれば、Release 3.0として2027年度に本格運用開始が予定されています。2026年5月現在は大規模パイロット(Release 2.0)の段階です。2026年夏にはRelease 2.1として国内LLM試験導入が予定されており、2026年12月にはRelease 2.2として高度なAIアプリの提供が計画されていますね。
Q6. 自治体が源内を参考に独自AIを構築する場合、何から始めればよいですか?
まずGitHubで公開されている2リポジトリ(genai-web・genai-ai-api)のREADMEと構成を確認することが出発点です。3クラウド対応テンプレート(AWS・Azure・GCP)が提供されているため、自組織のクラウド環境に合わせたものを選んで試験デプロイを行うのが現実的な手順です。セキュリティ要件の確認と小規模パイロットによる評価を経てから、本番展開を検討してください。
まとめ:源内から学ぶ行政AIの設計思想
「役所の仕事にAIは使えない」という時代は終わりました。源内が示したのは、行政業務へのAI導入において「何でもできる汎用ツール」と「特定業務に特化したAIアプリ」の2層を組み合わせる設計が有効だという知見なんです。OSS化により、その設計思想そのものが公開されています。
ざっくり整理すると、技術者・IT担当者が次にとるべきアクションはこの5つです。
- GitHubリポジトリ(genai-web・genai-ai-api)のソースコードと構成を確認する
- 3クラウド対応テンプレートの中から自組織のインフラに合うものを選定する
- 国産LLM7モデルの選定基準(ベンチマーク・セキュリティ要件・ハルシネーション対策)を自組織の評価軸として参照する
- 小規模パイロットから始め、フィードバック収集・ログ整備の仕組みを先に設計する
- 本格展開の前に「AIの出力を最終確認する人間の役割」を運用フローに明示する
源内の大規模パイロットが進む2026年〜2027年は、日本の公共セクターにおけるAI活用の基準が形成される時期です。その動向を注視し、自組織の設計に活かす入り口はすでに開いている。
お気軽にご相談ください
AIを使った業務効率化、社内ツール開発、既存プロダクトへのAI機能追加、受託開発全般——上流の企画段階から実装・運用まで、まとめてご相談いただけます。
「これってAIで解決できるの?」「どこから手をつければいい?」という入口のご相談大歓迎です。
具体的な仕様が固まる前の壁打ちフェーズからぜひお気軽にご相談ください。
参考情報
- デジタル庁 GENAI公式ページ(https://www.digital.go.jp/en/policies/genai)
- デジタル庁 GENAI OSS公開ニュース(https://www.digital.go.jp/en/news/907c8e5d-2f4f-4bd7-9400-37c9f4221d7d)
- GitHub genai-web(https://github.com/digital-go-jp/genai-web)
- GitHub genai-ai-api(https://github.com/digital-go-jp/genai-ai-api)



